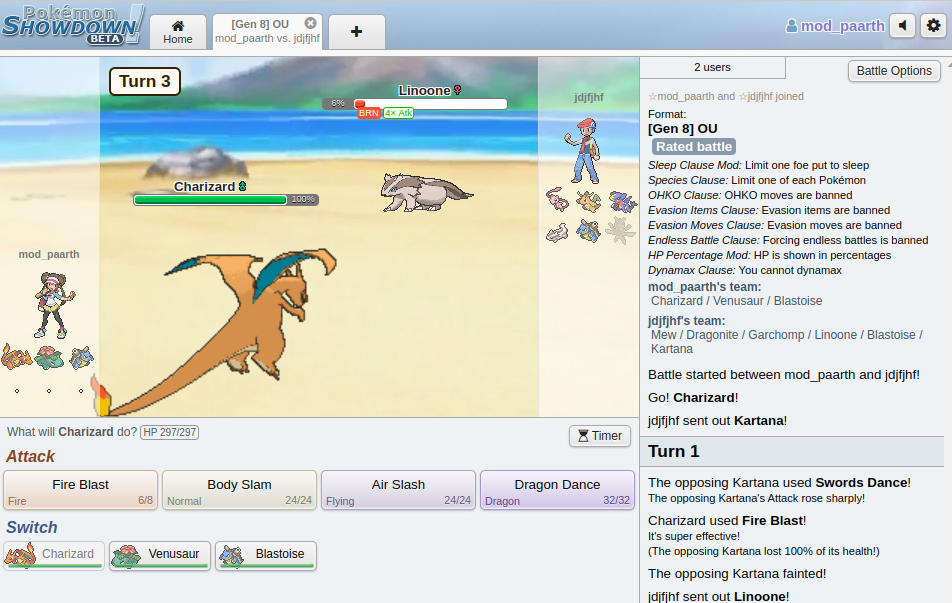
This repository contains various experiments I conducted to train a Pokemon Battle AI using RL. These experiments were conducted using poke-env and Pokemon Showdown for the environment, and PyTorch for model creation and training.
Some techniques I tried were DQN and Actor-Critic. The RL AI was able to beat a greedy AI over 80% of the time.
This repo was originally created for a final project in CS 687 at UMass Amherst. The final report for this project is available in this repo (report.pdf). This report contains more detailed information about the experiments that were conducted.